공공데이터 포털을 통해 대량의 데이터를 받아오면서 해당 데이터들을 DB INSERT 작업을 진행할 때 보다 빠르고 효율적으로 처리하기 위해 JDBC의 Batch Insert를 사용해 보기로 했다.
그리고 직접 JPA의 saveAll과 JDBC의 batch Insert를 비교하면서 성능 차이를 확인해 보겠다.
1. saveAll()
JPA에서 기본적으로 데이터 저장을 할 때 save()와 saveAll()을 통해 데이터 INSERT를 진행한다.
보통 save()는 개별 객체를 저장할 때 사용하고 saveAll()는 한 번에 여러 개의 객체를 저장할 때 사용한다.
원래 처음엔 대량의 데이터 INSERT 작업으로 saveAll()을 사용해서 작업을 진행하려 했었지만 saveAll()은 단건으로 INSERT 쿼리가 실행된다.
즉, 1000개의 데이터를 작업할 때 아래와 같은 INSERT 쿼리가 1000번 실행된다는 것이다.
insert into test_table (test_value1, test_value2) values ('t1', 't2');
insert into test_table (test_value1, test_value2) values ('t3', 't4');
insert into test_table (test_value1, test_value2) values ('t5', 't6');
insert into test_table (test_value1, test_value2) values ('t7', 't8');
또한, save()와 saveAll()을 사용하면 아래처럼 INSERT 쿼리가 실행되기 전 SELECT 쿼리가 실행되는 경우도 있다.
Hibernate:
select
tb1_0.test_value1,
tb1_0.test_value2,
tb1_0.test_value3,
from
test_table tb1_0
where
tb1_0.test_value1=?
Hibernate:
insert
into
test_table
(test_value1, test_value2, test_value3)
values
(?, ?, ?)
만일 1000개의 데이터를 saveAll()을 통해 INSERT를 진행하면 1000번의 SELECT 또한 실행이 될 것이다.
이는 쿼리 작업의 효율을 매우 떨어뜨리고 속도 또한 느려지기에 작업 시간이 오래 걸리는 상황이 생길 것이다.
그래서 INSERT 작업을 최적화하고 효율을 높이기 위해 Bulk INSERT 작업을 찾게 되었다.
2. Batch Insert
우선 단건 INSERT와 Bulk INSERT의 차이점을 알아보자
단건 INSERT는 아래와 같이 실행이 되고
insert into test_table (test_value1, test_value2) values ('t1', 't2');
insert into test_table (test_value1, test_value2) values ('t3', 't4');
insert into test_table (test_value1, test_value2) values ('t5', 't6');
insert into test_table (test_value1, test_value2) values ('t7', 't8');
Bulk INSERT는 아래와 같이 실행이 된다.
insert into
test_table (test_value1, test_value2)
values
('t1', 't2'), ('t3', 't4'), ('t5', 't6'), ('t7', 't8');
보시다시피 단건 INSERT와 달리 하나로 묶어서 INSERT 작업을 실행한다.
한눈에 보기에도 단건 INSERT 보다 성능이 좋아 보인다. 바로 코드 작성을 해보자
우선 application.properties에 아래와 같이 batch_size를 설정해 준다.
# application.properties
spring.jpa.properties.hibernate.jdbc.batch_size=1000
spring.jpa.properties.hibernate.order_updates=true
spring.jpa.properties.hibernate.order_inserts=true
그리고 기존에 사용하던 JPA repository에서 extends JpaRepository를 제거해 주고 클래스 형태로 작성해 준다.
// PopulationJan0sRepository.java
@Repository
public class PopulationJan0sRepository {
private final JdbcTemplate jdbcTemplate;
public PopulationJan0sRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public void batchInsert(List<Population0sDto> list) {
jdbcTemplate.batchUpdate(
"INSERT INTO population_jan_0s (admin_code, pop_age_m_0, pop_age_w_0, pop_age_m_1, " +
"pop_age_w_1, pop_age_m_2, pop_age_w_2, pop_age_m_3, pop_age_w_3) " +
"VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?)",
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setLong(1, list.get(i).getAdminCode());
ps.setLong(2, list.get(i).getPopAgeM0());
ps.setLong(3, list.get(i).getPopAgeW0());
ps.setLong(4, list.get(i).getPopAgeM1());
ps.setLong(5, list.get(i).getPopAgeW1());
ps.setLong(6, list.get(i).getPopAgeM2());
ps.setLong(7, list.get(i).getPopAgeW2());
ps.setLong(8, list.get(i).getPopAgeM3());
ps.setLong(9, list.get(i).getPopAgeW3());
}
@Override
public int getBatchSize() {
return list.size();
}
});
}
}
형태는 단순하니 작성하기 어렵지 않을 것이다. 아마 환경에 따라 추가해야 하는 내용도 있고 바꿔야 하는 부분도 있을 것이다. 해당 사항은 작업을 진행하면서 추후에 추가해 보겠다.
작성 후 repository의 batchInsert 메서드를 호출하여 사용해 주면 된다.
// PopulationJanService.java
@RequiredArgsConstructor
@Service
public class PopulationJanService {
private final PopulationJan0sRepository populationJan0sRepository;
@Transactional
public void populationJanUpdate(List<Population0sDto> list) {
try {
populationJan0sRepository.batchInsert(list); // 전달받은 list를 batchInsert에 넣어주기
} catch(Exception e) {
e.printStackTrace();
}
}
}
2. 성능 비교
1000개, 10000개, 100000개의 데이터 INSERT 작업을 할 때 saveAll()을 사용할 때와 batchInsert를 사용할 때의 차이점을 확인해 보겠다.
확인 방법은 해당 쿼리 시작 지점과 끝나는 지점에 스프링의 StopWatch 클래스를 사용하여 시간을 체크하였다.
// PopulationJanService.java
@RequiredArgsConstructor
@Service
public class PopulationJanService {
private final PopulationJan0sRepository populationJan0sRepository;
@Transactional
public void populationJanUpdate(List<Population0sDto> list) {
StopWatch stopWatch = new StopWatch();
try {
stopWatch.start(); // 시간체크 시작
populationJan0sRepository.batchInsert(list);
stopWatch.stop(); // 시간체크 끝
System.out.println("작업 시간 : " + stopWatch.getTotalTimeSeconds());
} catch(Exception e) {
e.printStackTrace();
}
}
}
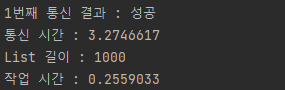
첫 번째로 1,000개의 List 데이터 INSERT 작업 결과이다.
- saveAll
- batchInsert
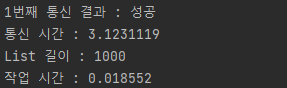
1000개의 데이터로도 확연히 차이가 나는 게 보인다. 그럼 List 데이터 수를 늘려보자
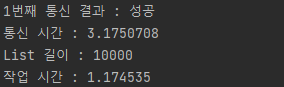
두 번째로 10,000개의 List 데이터 INSERT 작업 결과이다.
- saveAll
- batchInsert
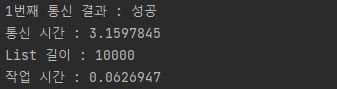
saveAll은 1초 단위로 들어섰지만 batchInsert는 큰 변화가 없다.
마지막으로 100,000개의 List 데이터 INSERT 작업 결과이다.
- saveAll
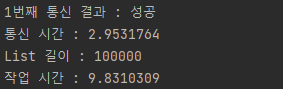
- batchInsert
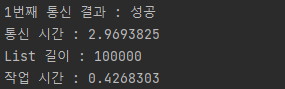
saveAll은 거의 10초가 걸리지만 batchInsert는 아직 1초도 안 걸린다. 성능상에서 차이가 확실하다.
직접 테스트를 해보며 비교를 해보니 작업 시간에서 차이점이 확연하게 보이고 batchInsert가 대량 데이터를 다룰 땐 좋은 기능이라는 것을 잘 알게 되었다.